Youtubeの各チャンネルのRSSフィードを取得する方法
Youtubeにはチャンネル毎にXML形式のフィードが割り当てられています。 これを確認するには、まずチャネルIDを確認する必要があります。 チャンネルIDはPCの場合、チャンネルトップの「さらに表示(他X件のリンク)」「チャンネルを共有」から「チャンネルIDをコピー」という項目がありコピーできます。 他にも、htmlのメタタグに割り当てられています。<meta itemprop="channelId" content="チャンネルID"> チャンネルIDを取得できたら以下のURLのパラメータ ...
Slackに使用規則を策定した話
Slackの運用課題に気づいたのは、社内で200〜300メッセージを超える長大なスレッドが多数存在することに衝撃を受け事からでした。 Slackのスレッド機能自体は優れていますが、適切に使用する必要があります。 200〜300メッセージに及ぶやり取りを全て追うことは非効率的です。 このような長大なスレッドの兆しがある場合、新しいチャンネルを作成するか、直接会議を開き、Google DocsやNotionなどの外部ドキュメントにまとめる方が生産的です。 ほとんどの社員があらゆるチャンネルに参加しており、かつ ...

Dockerでうっかりバージョンを上げると動かなくなることがある
※この記事は具体的なコマンドなどではなく、注意喚起です。 Docker自体をバージョンアップした時でも、新バージョンでの仕様変更や互換性の問題、バグの影響でイメージやコンテナが動かなくなることがあります。 顕著な症状として、DBコンテナの異常動作が挙げられます。具体的には、コンテナの再起動ループや、CPU使用率の急激な上昇(100%超過)による不安定な動作が観察されます。 これらの問題は、コンテナオーケストレーションレイヤーでの互換性の齟齬に起因することが多く見られます。 Docker Engineのバー ...
macOSでスクリーンショットの保存先が分からなくなった時の確認コマンド
まずmacOSでスクリーンショットの撮り方は以下の2つで。 1.[Macの画面全体をスクリーンショットする方法] 「shift」+「command」+「3」の3つを同時に押す 2.[Macの画面を一部をスクリーンショットする方法] 以下のボタンを押すと、十字ポインタが表示され、範囲指定ができます。 「shift」+「command」+「4」の3つを同時に押す 確認コマンド 上記での保存先が不明になった時、コマンドで確認できます。 コマンドは「スクリーンショットの保存先がどこに設定されているか」をmacOS ...

なぜlatestタグでの運用は危険なのか|バージョン固定の重要性
安定した運用を目指す場合は、特定のバージョンを指定して運用し、特定のタイミングで定期的にアップデートを行う方が望ましいです。 当然、アップデートはまず開発環境やテスト環境で検証を行い、本番環境への適用は慎重に進めるのが一般的なベストプラクティスです。 一般的にシステム運用において、バージョン指定を「latest」に固定するのは予期せぬ干渉を受けてしまうため、推奨されないことの方が多いです。 1. 予期しないアップデートによるリスク latestにすると、常に最新のバージョンを取得するため、アップデートのタ ...

ffmpegで16ビットのリニアPCMに変換する
Whisperモデルは、16kHzのサンプリングレートで16ビットのリニアPCM(WAV形式)にエンコードされた音声ファイルを想定しているようなので、ffmpegで文字起こしをした音声ファイルをエンコードします。 ## コマンドでffmpegを使ってwav形式にエンコードする ffmpeg -i "input.mp3" -ac 2 -ar 16000 -acodec pcm_s16le -f wav "output.wav" 各種オプションの説明。 -i "input.mp3": 入力ファイルを指定します ...
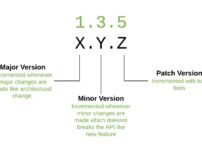
セマンティックバージョニングと各種バージョンアップの名称
x.y.zの形式はセマンティックバージョニング(Semantic Versioning)の標準に従う名称です。 これは、ソフトウェアのバージョン番号をどのように割り当て、増加させるべきかを定義したもので、xはメジャーバージョン、yはマイナーバージョン、zはパッチバージョンを表します。 これらのバージョン番号は以下のような意味を持ちます。 メジャーバージョン(x):互換性のないAPIの変更が含まれている場合に増加します。 マイナーバージョン(y):新機能を追加し、それが下位互換性を持つ場合に増加します。 パ ...
コマンドでmp4ファイルをmp3に変換する
ffmpegを使用してmp4ファイルをmp3に変換するためのコマンドです。 ## `-i input.mp4` : 入力ファイルを指定。この場合、`input.mp4`というファイル名 ## `-vn` : ビデオを無視。音声のみを抽出するためのオプション。 ## `-ar 44100` : オーディオのサンプリングレートを44100 Hzに設定。音声の品質を決定。 ## `-ac 2` : ステレオ(2チャンネル)オーディオを出力。こ左右のスピーカーから異なる音が出す。 ## `-b:a 192k` : ...

スクワッドモデル|Spotifyの組織構成からの学び
Spotifyは、アジャイル開発方法論を採用しており、その一環として「スクワッド」(Squad)と呼ばれる小さなクロスファンクショナルチームを組織内で使用しています。 スクワッドはKPIやCVR向上などやるべき事に焦点をあてたチーム分けです。 特定のプロダクトや機能に関連するタスクを負担し、そのタスクを実行するために必要なリソースを持つチームです。 以下は、Spotifyのスクワッドに関する特徴や役割についての詳細です。 特徴 これらの要素は、Spotifyが自分たちの仕事を組織化する際に、どのように人々 ...

Pull requestの適切的なサイズ
調査結果に基づかなくても体感で分かると思いますが、プルリクエスト(以下PR)のサイズはレビューの効率性と品質に大きな影響を与えます。 PRが小さいほど、レビューが容易で、フィードバックのサイクルが早く、問題の特定と修正が容易になります。 特定のタスクや変更に対応するために、PRを小さく、焦点を絞ったものに保つことが推奨されます。 Pull Request(PR)の適切なサイズについては、いくつかの調査があります。 Cisco SystemsのLOCとの相関 smartbearの調査では、PRの理想的なサイ ...